We system administrators handle many tasks each day for our customers. These tasks usually come in as tickets, asking us to build a new system or to change an existing system. The "standard" workflow for this is: Receive ticket, do ticket, lob ticket back over to customer asking them to test. While we're good at our jobs, we're not infallible. Every so often, the customer lobs the ticket right back saying "It doesn't work!" We then spend more time readdressing the ticket and usually find that it doesn't work because we omitted a step in our haste. Chagrined, we fix our work, test it, and then tell our customer that it should work now.
I would like to show you a better way. I've written before about how I've been using Cucumber for testing tickets. Today, I'd like to show you how you can too.
Intended audience
This is primarily aimed at system administrators but should benefit anyone who has operations duties. You should be familiar with programming or scripting. Specific familiarity with Ruby will be helpful but is not required.
Installing Cucumber
Cucumber is distributed as a Ruby gem. This means you'll need Ruby. On some platforms, you can install a package for Cucumber that will also install its prerequisites (for example, rubygem-cucumber on Fedora or cucumber on Debian). On others, you will need to install Ruby and rubygems support (on RHEL/CentOS, this would be the ruby and rubygems packages) and then install Cucumber and its prerequisites with this command: gem install cucumber
Getting started
To start work with Cucumber, you will need a directory structure like this:
features
|- steps
`- support
Tests for tickets go in the features directory. These files have the .feature extension. Each logical piece of work (e.g. a ticket, service, or system) will have its own file. (Cucumber has its origins in software testing so it calls these "features," corresponding to features in software being built.)
Step definitions (discussed below) go in the steps directory. These files have the .rb extension. Step definitions should be grouped logically in files so you can easily find them later.
Support files, e.g. functions or classes that are used in the step definitions, go in the support directory. These files also have the .rb extension.
To tell Cucumber you're using Ruby, it's customary to create a file named env.rb in the support directory. (You can use other languages, e.g. Python, with Cucumber. I will provide an example of this in the future.)
Anatomy of a Cucumber feature
Here is an example ticket written as a Cucumber feature:
Feature: New A record for QUUX.EXAMPLE.COM (20130708001)
Joe from Marketing wants us to add a host record
for quux.example.com so they can interact with a mockup
for a new website.
Scenario: A record for QUUX.EXAMPLE.COM
Given my DNS servers are:
|172.22.0.23|
|172.22.0.24|
|172.22.0.25|
When I query my DNS servers for the A record for "quux.example.com"
Then I should see that the A record response is "192.168.205.203"Each feature has a title that should reflect the purpose of the ticket. I like to include the ticket number in the title so I can easily refer back to the ticket. (I also include the date in the filename so I can easily find the feature or figure out when I did the work.)
Each feature may also have a description. The description should reflect the reason behind what you're testing for. It is optional and can be omitted. I tend to leave this out but you may find it useful if you share your features with your co-workers.
Each feature has one or more scenarios. These are the actual tests for the feature. How many scenarios you use will depend on personal judgment and the exact request you're handling. I tend to use a scenario for each discrete element of the ticket. For example, for an email account, I would have one scenario for logging in and one for any specific properties for the account.
Each scenario is composed of steps. A step is a discrete element of the text. A step usually starts with one of three keywords, Given, When, and Then. These keywords roughly equate to separate stages in the test:
Given steps are for items that are already in place that impact the test. For example, if your test relies on specific pieces of infrastructure or on a specific state in your environment, these would be Givens.When steps represent actions you would take to verify the ticket. These might include running commands on a system or going to a web page.Then steps represent the outcome of the actions taken in the When steps.
(Whens and Thens are generally written as first person sentences to reflect that these are actions you would take or outcomes you would see.)
Step definitions
Once you've specified the feature, its scenarios, and its scenarios' steps, you then need to tell Cucumber how to execute the steps. You do this via step definitions. As noted above, step definitions are stored in Ruby files in the steps subdirectory.
A step definition will look like this:
Given(/^a step definition$/) do
# code goes here
end
A step definition starts with one of the three keywords, Given, When, or Then. This is followed by a regular expression that matches the step for this definition. Following this is the block of code to run for the step.
You can use grouping in the regular expression to capture any data embedded in the step. Any captured groups are then passed along to the block. For example, given this step definition:
When(/^I query my DNS servers for the A record for "(.*?)"$/) do |host|
# code goes here
end
If a scenario has the step "When I query my DNS servers for the A record for "quux.example.com"", it would execute using the above step definition with the host variable set to "quux.example.com".
Walkthrough
Let's see this in action. To follow along locally, you'll need to have Vagrant installed. To get started, clone this git repo and follow the instructions in the README.md file.
The environment consists of four systems: a system to run Cucumber on (tester), a master DNS server (dns_master), and two slave DNS servers (dns_slave1 and dns_slave2). The two slave DNS servers transfer zones from the master DNS server.
First, we'll need to set up the directories. Connect to tester using SSH (vagrant ssh tester). Once there, create the features directory and then the steps and support directories underneath it.
In the support directory, create a blank file named env.rb. This tells Cucumber that we will be using Ruby for step definitions.
Now we're ready to work through a scenario. Let's say we receive the ticket below:
From: Joe in Marketing
Subject: Need a new hostname
Our web design firm has created a mockup of our new website. We'd like
to test the mockup with our marketing tools. Would you please set up
QUUX.EXAMPLE.COM to point to our server at 192.168.205.203?
From this, we need to figure out an appropriate test for it. We want to make sure that quux.example.com resolves to 192.168.205.203. Fortunately, we already have a test for this: the example feature from above. Let's use that.
In the features directory, create a file named 20130708_example.feature. Copy the example feature from above and paste it into that file.
Our next goal is to get the test to fail. We need to prove that the test fails without the change in place. Otherwise, how do we know that our work actually causes the test to pass?
At the shell prompt, run this command while in the features directory:
cucumber ../features/20130708_example.feature
You should see output like:
[vagrant@tester features]$ cucumber ../features/20130708_example.feature
Feature: New A record for QUUX.EXAMPLE.COM (20130708001)
Joe from Marketing wants us to add a host record
for quux.example.com so they can interact with a mockup
for a new website.
Scenario: A record for QUUX.EXAMPLE.COM # ../features/20130708_example.feature:6
Given my DNS servers are: # ../features/20130708_example.feature:7
| 172.22.0.23 |
| 172.22.0.24 |
| 172.22.0.25 |
When I query my DNS servers for the A record for "quux.example.com" # ../features/20130708_example.feature:11
Then I should see that the A record response is "192.168.205.203" # ../features/20130708_example.feature:12
1 scenario (1 undefined)
3 steps (3 undefined)
0m0.002s
You can implement step definitions for undefined steps with these snippets:
Given(/^my DNS servers are:$/) do |table|
# table is a Cucumber::Ast::Table
pending # express the regexp above with the code you wish you had
end
When(/^I query my DNS servers for the A record for "(.*?)"$/) do |arg1|
pending # express the regexp above with the code you wish you had
end
Then(/^I should see that the A record response is "(.*?)"$/) do |arg1|
pending # express the regexp above with the code you wish you had
endAs you can see in the output above, Cucumber doesn't know how to run our test because there are no step definitions. We need to fix this before we can get the test to fail.
Cucumber helpfully provides skeletal step definitions. Let's copy these and then paste them into a new file in the steps directory named dns_steps.rb.
Let's rerun the Cucumber command. You should see output like:
[vagrant@tester features]$ cucumber ../features/20130708_example.feature
Feature: New A record for QUUX.EXAMPLE.COM (20130708001)
Joe from Marketing wants us to add a host record
for quux.example.com so they can interact with a mockup
for a new website.
Scenario: A record for QUUX.EXAMPLE.COM # features/20130708_example.feature:6
Given my DNS servers are: # features/steps/dns_steps.rb:1
| 172.22.0.23 |
| 172.22.0.24 |
| 172.22.0.25 |
TODO (Cucumber::Pending)
./features/steps/dns_steps.rb:3:in `/^my DNS servers are:$/'
features/20130708_example.feature:7:in `Given my DNS servers are:'
When I query my DNS servers for the A record for "quux.example.com" # features/steps/dns_steps.rb:6
Then I should see that the A record response is "192.168.205.203" # features/steps/dns_steps.rb:10
1 scenario (1 pending)
3 steps (2 skipped, 1 pending)
0m0.004sWe see that Cucumber now knows how to run the steps and that the first one is in the state "pending." In order to get this step to pass, we'll need to define it. Let's go ahead and do that.
Recall that our first step is:
Given my DNS servers are:
|172.22.0.23|
|172.22.0.24|
|172.22.0.25|
We use this step to define the DNS servers we want to deal with.
Open dns_steps.rb. Find the skeleton for the first step:
Given(/^my DNS servers are:$/) do |table|
# table is a Cucumber::Ast::Table
pending # express the regexp above with the code you wish you had
end
Change that to:
Given(/^my DNS servers are:$/) do |servers|
@nameservers = servers.raw.map {|row| row.first}
endThe new code for the step definition takes the IPs in the table and stores them as an array in the class variable @nameservers. Since class variables are shared between steps in a scenario, this lets us use the IPs in later steps.
(I haven't discussed tables since they're a more advanced topic. I will talk about them in a future post. The curious can look at Cucumber's documentation.)
Save the file and rerun the feature. You should see output like:
[vagrant@tester features]$ cucumber ../features/20130708_example.feature
Feature: New A record for QUUX.EXAMPLE.COM (20130708001)
Joe from Marketing wants us to add a host record
for quux.example.com so they can interact with a mockup
for a new website.
Scenario: A record for QUUX.EXAMPLE.COM # ../features/20130708_example.feature:6
Given my DNS servers are: # steps/dns_steps.rb:1
| 172.22.0.23 |
| 172.22.0.24 |
| 172.22.0.25 |
When I query my DNS servers for the A record for "quux.example.com" # steps/dns_steps.rb:5
TODO (Cucumber::Pending)
./steps/dns_steps.rb:6:in `/^I query my DNS servers for the A record for "(.*?)"$/'
../features/20130708_example.feature:11:in `When I query my DNS servers for the A record for "quux.example.com"'
Then I should see that the A record response is "192.168.205.203" # steps/dns_steps.rb:9
1 scenario (1 pending)
3 steps (1 skipped, 1 pending, 1 passed)
0m0.003sOur first step passes! Now Cucumber is saying that the second step is pending. Let's define that step now.
Recall that our second step is:
When I query my DNS servers for the A record for "quux.example.com"
Reopen dns_steps.rb. Find the skeleton for the second step:
When(/^I query my DNS servers for the A record for "(.*?)"$/) do |arg1|
pending # express the regexp above with the code you wish you had
end
Change that to:
When(/^I query my DNS servers for the A record for "(.*?)"$/) do |host|
responses = {}
@nameservers.each do |server|
resolver = Net::DNS::Resolver.new(:nameservers => server, :recursive => false, :udp_timeout => 15)
responses[server] = resolver.query(host, Net::DNS::A)
end
@nameservers.each do |server|
next if @nameservers.first == server
responses[@nameservers.first].answer.map {|r| r.to_s}.sort.should \
eq(responses[server].answer.map {|r| r.to_s}.sort),
"DNS responses from #{@nameservers.first} and #{server} don't match!"
end
@response = responses[@nameservers.first]
@host = host
endThis code does four things:
- It queries each of the DNS servers specified in
@nameservers for the A record(s) for the name stored in the host variable (for this example, "quux.example.com").
- It then verifies that the response from all of the DNS servers is identical. If it's not, it fails the step with the reason "DNS servers don't match."
- It then stores the response of the first DNS server in the
@response class variable.
- It stores the
host variable in the @host class variable so we can use it in error messages in later steps.
Let's look closer at the second block. Do you see this code in the middle?
This is an example of an RSpec expectation. We use expectations to verify conditions that should be true (the should expectation) or that should not be true (the should_not expectation). If the expectation is not correct (e.g. the condition is false but it's expected to be true), it will cause the step to fail.
(RSpec is another BDD testing framework. For now, all you need to know is that Cucumber uses RSpec's expectations and matchers. This is worth knowing if you need to do something complex but isn't as important for most tasks. Thoughtbot has a PDF of common RSpec matchers.)
Why do we test validity in a When step? Here, we're conducting a sanity check on the DNS server responses. If the responses aren't the same, there's an issue with the DNS servers and any later tests we conduct will be invalid. Since we want to get feedback as soon as possible, we want to fail as soon as possible and so we do a sanity check here rather than in a later step.
Add the following to the top of dns_steps.rb:
require 'rubygems'
require 'net/dns'
Save the file and rerun the Cucumber command. You should see output like:
[vagrant@tester features]$ cucumber ../features/20130708_example.feature
Feature: New A record for QUUX.EXAMPLE.COM (20130708001)
Joe from Marketing wants us to add a host record
for quux.example.com so they can interact with a mockup
for a new website.
Scenario: A record for QUUX.EXAMPLE.COM # ../features/20130708_example.feature:6
Given my DNS servers are: # steps/dns_steps.rb:4
| 172.22.0.23 |
| 172.22.0.24 |
| 172.22.0.25 |
When I query my DNS servers for the A record for "quux.example.com" # steps/dns_steps.rb:8
Then I should see that the A record response is "192.168.205.203" # steps/dns_steps.rb:26
TODO (Cucumber::Pending)
./steps/dns_steps.rb:27:in `/^I should see that the A record response is "(.*?)"$/'
../features/20130708_example.feature:12:in `Then I should see that the A record response is "192.168.205.203"'
1 scenario (1 pending)
3 steps (1 pending, 2 passed)
0m2.703sNow the second step passes! On to the third step. Recall that our third step is:
Then I should see that the A record response is "192.168.205.203"
Reopen dns_steps.rb. Find the skeleton for the third step:
Then(/^I should see that the A record response is "(.*?)"$/) do |arg1|
pending # express the regexp above with the code you wish you had
end
Change that to:
Then(/^I should see that the A record response is "(.*?)"$/) do |ip|
@response.should_not be_nil, "There is no DNS response. Did you run a query?"
@response.answer.should_not be_empty, "There are no records in the response."
@response.answer.length.should eq(1),
"There should only be one record. Instead, there are #{@response.answer.length} records."
@response.answer.first.address.should eq(ip),
"The current A record is #{@response.answer.first.address}, not #{ip}."
endThis code performs the following checks:
- It verifies that
@response is defined. If it's not, something undesirable has happened (for example, there is a bug in a When step or an appropriate When step had not been used) and any of our tests will fail.
- It verifies that
@response's field answer is not empty. The resolve method used in the previous step sets answer to an array of resource records. If the array is empty, there were no records and we should fail the step now since there isn't an A record pointing to the IP.
- It verifies that
@response's field answer only has one element. If there are multiple records, there will be multiple elements. Since we only want a single record, this should also fail.
- It verifies that the first (and only) element in
@response's field answer is an A record pointing to the desired IP.
Note that each different condition has its own failure message. This helps us determine exactly where the step failed.
Save the file and rerun the Cucumber command. You should see output like:
[vagrant@tester features]$ cucumber ../features/20130708_example.feature
Feature: New A record for QUUX.EXAMPLE.COM (20130708001)
Joe from Marketing wants us to add a host record
for quux.example.com so they can interact with a mockup
for a new website.
Scenario: A record for QUUX.EXAMPLE.COM # ../features/20130708_example.feature:6
Given my DNS servers are: # steps/dns_steps.rb:4
| 172.22.0.23 |
| 172.22.0.24 |
| 172.22.0.25 |
When I query my DNS servers for the A record for "quux.example.com" # steps/dns_steps.rb:8
Then I should see that the A record response is "192.168.205.203" # steps/dns_steps.rb:27
There are no records in the response. (RSpec::Expectations::ExpectationNotMetError)
./steps/dns_steps.rb:29:in `/^I should see that the A record response is "(.*?)"$/'
../features/20130708_example.feature:12:in `Then I should see that the A record response is "192.168.205.203"'
Failing Scenarios:
cucumber ../features/20130708_example.feature:6 # Scenario: A record for QUUX.EXAMPLE.COM
1 scenario (1 failed)
3 steps (1 failed, 2 passed)
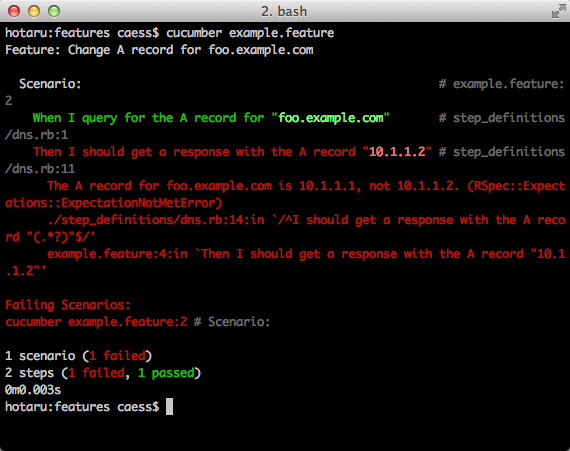
0m0.388sAs you can see, our test has failed because the third step failed. That step failed because there are no A records for quux.example.com. Our feature has failed in the expected manner. Success! (Of sorts, anyway.) We can now implement the change needed for the ticket.
In another window, connect to dns_master using SSH (vagrant ssh dns_master). Go to /home/vagrant/named and edit the file example.com. Add the following A record at the end of the file:
quux IN A 192.168.205.203
This is important: Do not increment the serial number for now. Our zone file should now look like this (your serial number may differ):
$TTL 300
example.com. IN SOA ns1.example.com. hostmaster.example.com. (
1375624788 ; Serial
3h ; Refresh
15 ; Retry
1w ; Expire
300 ; Minimum
)
IN A 192.168.205.199
IN NS ns1.example.com.
IN NS ns2.example.com.
IN TXT "U3VuIEF1ZyAwNCAxMDoxOTowOSAtMDQwMCAyMDEz"
; Hosts
www IN CNAME example.com.
foo IN A 192.168.205.198
ns1 IN A 172.22.0.24
ns2 IN A 172.22.0.25
quux IN A 192.168.205.203Save the file and close your editor. At the command prompt, run this command: sudo rndc reload
The change made to the zone file will now be loaded by the master DNS server. However, since we did not increment the serial number, the change will not be picked up by the slave DNS servers. (This is probably the most common error I make when updating zone files.)
Go back to the first window and rerun the Cucumber command. You should see output like:
[vagrant@tester features]$ cucumber ../features/20130708_example.feature
Feature: New A record for QUUX.EXAMPLE.COM (20130708001)
Joe from Marketing wants us to add a host record
for quux.example.com so they can interact with a mockup
for a new website.
Scenario: A record for QUUX.EXAMPLE.COM # ../features/20130708_example.feature:6
Given my DNS servers are: # steps/dns_steps.rb:4
| 172.22.0.23 |
| 172.22.0.24 |
| 172.22.0.25 |
When I query my DNS servers for the A record for "quux.example.com" # steps/dns_steps.rb:8
DNS responses from 172.22.0.23 and 172.22.0.24 don't match! (RSpec::Expectations::ExpectationNotMetError)
./steps/dns_steps.rb:18
./steps/dns_steps.rb:15:in `each'
./steps/dns_steps.rb:15:in `/^I query my DNS servers for the A record for "(.*?)"$/'
../features/20130708_example.feature:11:in `When I query my DNS servers for the A record for "quux.example.com"'
Then I should see that the A record response is "192.168.205.203" # steps/dns_steps.rb:27
Failing Scenarios:
cucumber ../features/20130708_example.feature:6 # Scenario: A record for QUUX.EXAMPLE.COM
1 scenario (1 failed)
3 steps (1 failed, 1 skipped, 1 passed)
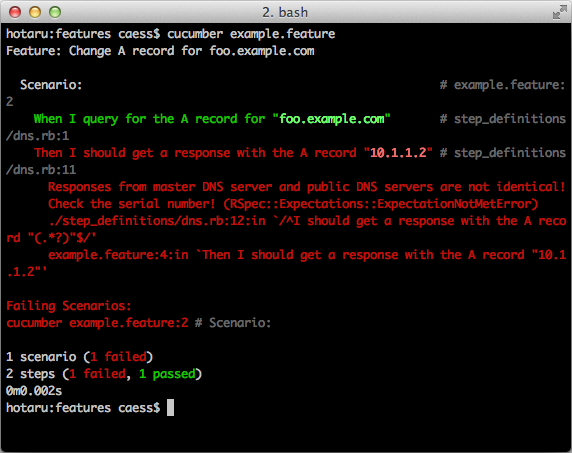
0m0.449sAs you can see, the feature has failed because the DNS server responses don't match.
Go back to the second window and edit the zone file again. This time, increment the serial number. The zone file should now look like this:
$TTL 300
example.com. IN SOA ns1.example.com. hostmaster.example.com. (
1375624789 ; Serial
3h ; Refresh
15 ; Retry
1w ; Expire
300 ; Minimum
)
IN A 192.168.205.199
IN NS ns1.example.com.
IN NS ns2.example.com.
IN TXT "U3VuIEF1ZyAwNCAxMDoxOTowOSAtMDQwMCAyMDEz"
; Hosts
www IN CNAME example.com.
foo IN A 192.168.205.198
ns1 IN A 172.22.0.24
ns2 IN A 172.22.0.25
quux IN A 192.168.205.203Save the file and exit your editor. Run this command to reload the zone file: sudo rndc reload
Since we incremented the serial number this time, the changes to the zone file are pushed out to the slave DNS servers.
Go back to the first window and rerun the Cucumber command. You should see output like:
[vagrant@tester features]$ cucumber ../features/20130708_example.feature
Feature: New A record for QUUX.EXAMPLE.COM (20130708001)
Joe from Marketing wants us to add a host record
for quux.example.com so they can interact with a mockup
for a new website.
Scenario: A record for QUUX.EXAMPLE.COM # ../features/20130708_example.feature:6
Given my DNS servers are: # steps/dns_steps.rb:4
| 172.22.0.23 |
| 172.22.0.24 |
| 172.22.0.25 |
When I query my DNS servers for the A record for "quux.example.com" # steps/dns_steps.rb:8
Then I should see that the A record response is "192.168.205.203" # steps/dns_steps.rb:27
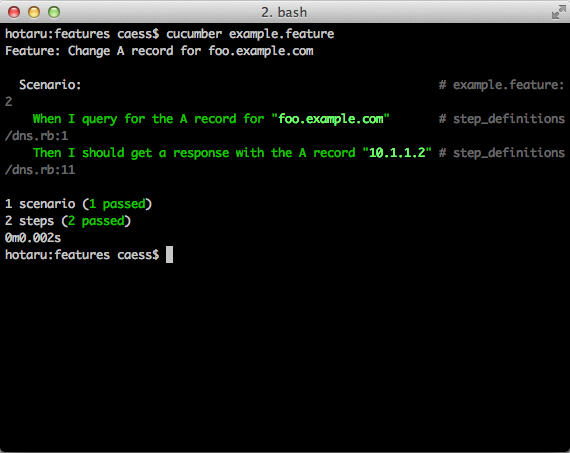
1 scenario (1 passed)
3 steps (3 passed)
0m0.395sAs you can see, the test passed. This means we're done! Now we can tell Joe that we've added the A record for him and we can move on to the next ticket.
Wrap-up
You should now have an idea of how to use Cucumber for use with tickets (or other tasks you have to do). If there are things about Cucumber that you need more information on, please see the Cucumber documentation. If something about this process confuses you, leave a comment and I'll try to help.
To learn more
There's a fair bit I haven't mentioned. I'll mention some of this in future blog posts.
If you want to see other examples, the features directory in the git repository for the demo environment contains the Cucumber features I used when building it and making sure it worked as expected.
If you're impatient and want to learn more now, you can read the Cucumber documentation and examples. The Pragmatic Bookshelf has published books on Cucumber, The Cucumber Book, and RSpec, The RSpec Book.